

Por estadística, muchos de quienes estéis curioseando este post habréis leído El infinito en un junco o Sapiens. En ambos libros sus autores celebraban la trascendencia que supuso la biblioteca de Alejandría, como idea y como proyecto, para la humanidad.
Pero, además, y esto es lo interesante, tanto Vallejo como Harari subrayan el esfuerzo que significó construir una técnica para recuperar la información en aquel contexto de exceso.
A medida que Ptolomeo iba acumulando papiros, Zenódoto y Calímaco -dos de los bibliotecarios avant la lettre- se vieron en la obligación de ingeniar un sistema para organizar la información. De otra forma, los documentos se acumulaban sin orden ni concierto. Así que, como respuesta a dicha necesidad, Calímaco sembró las bases de la catalogación moderna.
Dos mil años después, y recordando las energías que empleó Google para escanear millones de libros entre 2007 y 2012 (spoiler: desistieron), resulta inevitable concluir que ordenar el exceso de información es un reto eterno.
Y en los libros, mucho más.
Los datos sobre los datos
Con el asentamiento del presente contexto digital, se ha hablado mucho en el sector editorial estos últimos 10 o 15 años sobre los libros y sus metadatos, Arantxa Mellado mediante.
No nos engañemos, pese a ser uno de los temas más tediosos en la bella e idílica tarea diaria de un editor, tener optimizada la metadata de un libro es CLAVE para poder alcanzar al público que demanda ese contenido.
Ya no estamos en el contexto del 2005 y cualquier editor sabe que en nuestro mundo hay menos estanterías que antes. Unelibros, por ejemplo, se ha reconvertido ahora en Unelibros blog, y ya no se publica en papel.
Es por esto que, en este nuevo Unelibros blog, no queremos dejar pasar la oportunidad de fijar una entrada que hable sobre los metadatos, que cree conversación y, es más, que vaya actualizándose con información relevante sobre los metadatos en los libros.
Una idea de estándar
En España tenemos la suerte de que el sector impulsara DILVE (Distribuidor de Información del Libro Español en Venta) como herramienta en un momento determinante. El servicio que presta DILVE como mecanismo de estandarización del libro comercial es vital para nuestro mercado.
Quizás ahora que todo el sector disfruta de sus beneficios no reparamos en qué podría haber sucedido si DILVE no existiera. Pero, si para quienes lo usamos diariamente ya supuso un pequeño trabajo el mapeo de IBIC a Thema (por no hablar de las antiguas CDU), no quiero ni imaginar qué hubiera pasado si la desestandarización hubiera partido desde más atrás. No perdamos de vista que la creatividad del ser humano ha dado forma a infinitas maneras de crear estándares, como describe Jenn Riley en el siguiente trabajo.
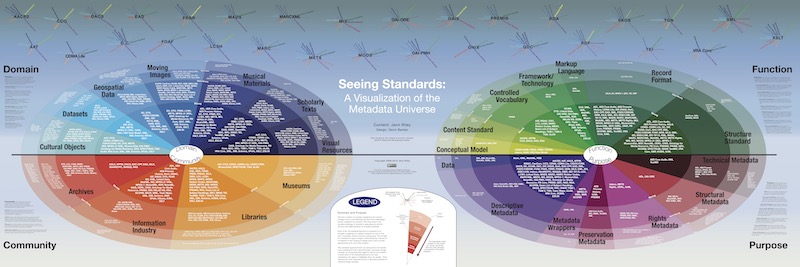
Fuente: Riley, Jenn, Seeing Standards: A Visualization of the Metadata Universe, http://jennriley.com/metadatamap (CC BY-NC-SA 3.0 US)
Por tanto, la tarea de DILVE por homogeneizar un protocolo colectivo es un logro absolutamente merecedor de todo elogio.
Tengamos en cuenta que, en el mercado occidental por excelencia (los EE.UU.), dicha iniciativa, como bien detalla Mike Shatzkin en su blog, partió de un player privado como es Ingram, base sobre la que se construyó la arquitectura de datos de esa empresa llamada Amazon.
Pero esta es otra historia.
El ciclo vital de los metadatos
Como ya hemos mencionado arriba, unos buenos metadatos son el mejor puente para que los editores puedan llegar directamente a sus lectores más adecuados.
Este proceso virtuoso lo encontramos detallado en la estupenda infografía de The metadata Handbook que adjuntamos a continuación.
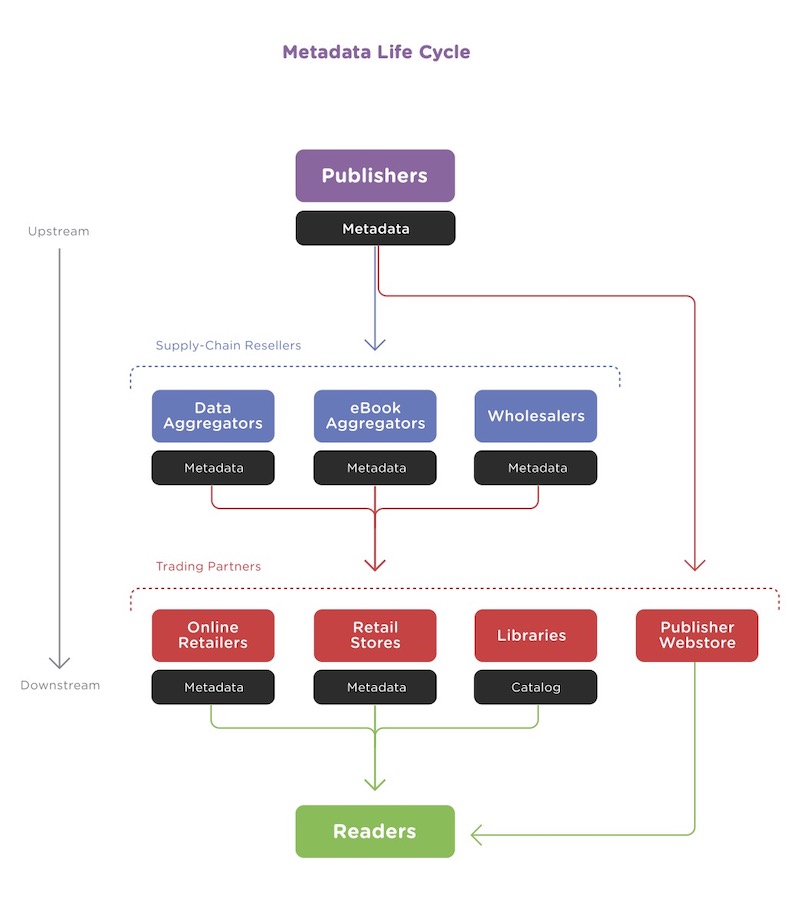
Esta imagen ya tiene unos años pero el proceso sigue siendo esencialmente el mismo para la edición tradicional, y es un ejercicio de síntesis magnífico de la cadena de valor del metadato. La versión en español, El manual de los metadatos, la podéis encontrar en el site de Datalibri.
En un intento, por otra parte, de aterrizar la idea del metadato en sí para la cadena de valor del sector del libro y no confundirnos, debemos definir qué estamos hablando cuando nos referimos al metadato. Habitualmente, el metadato (como bien ideó Philip R. Bagley, el creador del término y su concepto) puede hacer referencia a miles de características del objeto referenciado.
Sin embargo, el uso común del término en nuestro sector hace referencia a los datos esenciales del libro en su cadena comercial. Eso no quita, y como ya hemos visto en la estandarización de Reely, que haya metadatos para todos los gustos y, sobre todo, necesidades -principalmente bibliotecarias y documentales-, que se escapen de esta aproximación terminológica.
Por resumir, la clasificación que hace Richard Gartner en Metadata sigue siendo ejemplar de lo que podemos establecer como un esquema básico de una estructura de metadatos.

No estaría mal que alguien se atreviera a verterlo al español. Así como idea.
Por último, unas “buenas prácticas” de metadatos
En mi opinión, y aunque suene contradictorio en este punto, hablar de buenas prácticas de metadatos, poner infografías, listar tareas óptimas para ofrecer una buena catalogación y visibilidad, blablablá, no tiene mucho sentido si desde la propia editorial que produce el contenido no se considera que los metadatos son una parte central de su propuesta de valor.
La mejor práctica para tener un buen flujo de metadatos es la convicción de que dicha tarea es determinante. Sin esta convicción, sin este mindset, de poco sirve revisar acciones. La experiencia nos dice que nadie que no interiorice la importancia de esta dimensión editorial lo va a llevar a cabo.
Dicho lo cual, os voy a compartir tres recursos y algunas reflexiones personales de estos años de experiencia en Unebook, por si os sirven de ayuda (y con la idea de poder ir actualizándolo de forma periódica). Ahí van:
- Insisto en lo anterior: DILVE es sin duda la mejor herramienta existente en el sector para la administración de metadatos en el canal comercial del libro. Ahora que tienen una página web más moderna (afortunadamente), podemos encontrar esta estupenda infografía enlazada sobre calidad de metadatos que todo editor competente debería tener enmarcada en su despacho. Esos son los 23 campos son fundamentales.
- El mejor compendio abierto sobre guías de catalogación existente, a mi juicio, lo podemos encontrar en la página del proyecto Metadata 2020. En su Guía de buenas prácticas sobre metadata se pueden encontrar desde los enlaces a las guías de catalogación de las universidades de Stanford o Cornell, hasta los detalles de catalogación de los ORCID, Crossref o Pubmed. Este es un recurso para dedicarle semanas y orientado a un editor o investigador experimentado.
- El informe de Nielsen que tradujo Onixsuite al español en 2016 está un poco desactualizado pero todavía contiene partes muy válidas sobre el descubrimiento de libros en la red, así como un aparato estadístico exhaustivo de los casos de EE.UU. y Reino Unido. Aquí encontramos este contenido, moderadamente resumido, en una ppt posterior.
Algunos consejos personales sobre metadatos digitales en los libros. Para ilustrar cada idea trataré de poner ejemplos no hispanos:
- Diseñar la imagen de cubierta pensando también en lo digital. Lo ideal sería tener una imagen de cubierta en la que el usuario pudiera leer claramente el título y el autor en el pic tipo sello que se publique en la estantería digital de una librería online. Pero esto es algo que no siempre se consigue, y generalmente por motivos obvios. Es el caso, por ejemplo, de la colección Unseld de la editorial alemana Suhrkamp. Cada imagen de cubierta es un misterio para el usuario que no haga clic. Mariana Eguaras tiene un decálogo sobre diseño de cubiertas muy interesante y divertido.
- La coherencia y uniformidad en el diseño editorial de colecciones es fabulosa para identificar a ojo los libros de un sello en las baldas de una librería (que se lo pregunten a Herralde y a su peste amarilla). Pero quizá resulte confuso en una página web, donde el ojo busca de otra forma. Pongamos el ejemplo de dos editores que personalmente me parecen excelentes, pero cuyas imágenes de cubierta de sus títulos son idénticas las unas a las otras: el primero, la editorial inglesa Fitzcarraldo; el segundo, la clásica colección de Reclam. Entiendo que un editor deba pensar en global (economía de diseño, porcentaje de venta por canal, etc.), pero en digital esta no es una práctica deseable.
- Títulos fáciles y atractivos. El Premio Guinness al título más largo de un libro lo ganó Vityala Yethindra con una obra sobre las anélidas de más de 26.000 caracteres. A no ser que tu objetivo sea superarlo, es recomendable abreviar el título. La ficha de producto de muchos ecommerces no opera correctamente con títulos muy largos (y la atención de los usuarios, tampoco). Aquí tenemos un pequeño ejemplo sobre una historia de China cuyo título podría haber sido un subtítulo.
- Categoría adecuada y correcta (es decir, catalogación correcta de la materia Thema). Aquí hay cierta controversia, porque muchas supuestas “buenas prácticas” sobre metadatos recomiendan modificar la categoría del libro para que la obra salga destacada en las listas de Amazon, principalmente. Pero, aunque tu cómic autoeditado quizá pueda estar el primero en la lista de los más vendidos del día en la categoría de “Libros de pesca con mosca” de Amazon, hay lectores que pasaron por alto tu libro al no estar en la lista de la categoría adecuada. Por ejemplo, entiendo la oportunidad que le brinda al editor catalogar La clave secreta del universo, de Stephen Hawking, bajo la categoría de “Ciencia Ficción para niños” en Amazon, pero todos concluiremos que no es la categoría más adecuada.
- Nombrar a un autor con nombre y apellido. Y siempre con los mismos. Esto, al menos por parte del editor, debería ser algo sagrado. Pero en no pocas ocasiones nos encontramos con autores que en una monografía o artículo aparecen como Juan Pérez Criado, en otro como Juan P. Criado y en otro como J. Pérez Criado. Y esto solo porque, por ejemplo, la persona responsable de catalogar cada obra lo hizo con distintos criterios y no hay uniformidad. Las normas APA son una buena guía para resolver dudas en las nomenclaturas de autores. Se me viene a la cabeza el caso del sociólogo John B. Thompson, porque es ejemplar; en algunos casos aparece como John Thompson, Los media y la modernidad, en otros como John B. Thompson, El escándalo político, y en la Wikipedia como John Brookshire Thompson.
- Evitar el “Varios Autores” o VV.AA. en las obras colectivas. Siempre hay un editor, coordinador, compilador, etc., que coordina el texto; o un autor principal; o alguien a quien acreditar algún mérito. Siempre es más adecuado dejar a algún autor fuera que invisibilizarlos a todos.
- El índice o tabla de contenidos es fundamental en las obras académicas, textos colectivos y en monografías científicas en general.
- Por último, recuerda, editor, que si no eres tú quien proporciona los metadatos, será otro quien lo haga, y puede ser que no estés conforme con lo que leas.
Espero que os sea de ayuda.


